构建海量数据仓库解决方案 核心存储架构设计与实践
随着企业数据量的爆炸式增长,传统数据仓库在处理海量数据时面临存储成本高、扩展性差、性能瓶颈等严峻挑战。构建一个面向海量数据的数据仓库存储解决方案,已成为企业实现数据驱动决策的关键基础。本文将深入探讨海量数据仓库的存储架构核心要素与实践路径。
一、 海量数据存储的核心挑战与设计原则
海量数据仓库的存储设计,首要目标是应对数据规模大、增长快、类型多、访问模式复杂等挑战。其核心设计原则包括:
- 可扩展性:存储架构必须能够水平扩展,以应对数据量从TB到PB乃至EB级的增长,实现存储容量与计算能力的线性增长。
- 成本效益:在保证性能与可靠性的前提下,采用分层存储策略(热、温、冷数据),结合对象存储等低成本介质,显著降低总体拥有成本(TCO)。
- 高性能:针对即席查询、批量分析、实时流处理等不同负载,优化数据布局、索引和压缩算法,减少I/O瓶颈,提供高吞吐与低延迟的数据访问能力。
- 高可靠与高可用:通过多副本、纠删码等技术保障数据持久性,并通过跨机房、跨区域部署实现业务连续性。
- 架构解耦与弹性:推动存储与计算资源的解耦,使两者能够独立扩展,提升资源利用率和架构灵活性。
二、 主流存储架构与技术选型
现代海量数据仓库的存储方案已从传统的共享磁盘(如SAN/NAS)演进到分布式、云原生的架构。
1. 分布式文件系统与对象存储
* HDFS:作为Hadoop生态的基石,适合存储大规模非结构化与半结构化数据,具有高吞吐、高容错特性,但原生架构存在单点故障和计算存储耦合的问题。
- 云对象存储(如AWS S3, Azure Blob Storage, 阿里云OSS):已成为数据湖存储的事实标准。它提供近乎无限的扩展能力、极高的耐久性和极低的存储成本,完美支持存储计算分离架构。现代数据仓库(如Snowflake, BigQuery, Databricks)大多将对象存储作为核心持久层。
2. 列式存储格式
为优化分析查询性能,海量数据仓库普遍采用列式存储格式,仅读取查询所需的列,极大减少I/O。主流格式包括:
- Parquet:支持高效的压缩和编码,具有优秀的查询性能和广泛的生态兼容性(Spark, Presto, Hive等)。
- ORC:Hive生态中性能优异的列存格式,特别适合Hive查询优化。
- CarbonData/Delta Lake/Iceberg/Hudi:这些是更高级的“表格式”,在Parquet/ORC等文件格式之上,增加了ACID事务、数据版本管理、增量更新等高级功能,是实现高效数据湖仓一体化的关键。
3. 存储计算分离架构
这是当前的主流趋势。将数据持久化在共享、可扩展的对象存储中,计算集群(如Spark, Presto, 数据仓库引擎)变为无状态节点,按需弹性伸缩。此架构带来了巨大的成本与灵活性优势:计算资源可独立优化,存储成本大幅降低,并易于实现多引擎并发访问。
三、 分层存储与数据生命周期管理
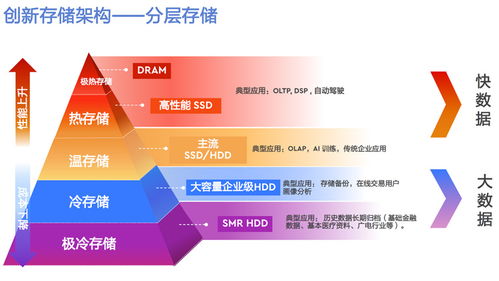
根据数据的访问频率和性能要求,实施智能的分层存储策略是控制成本的关键:
- 热存储层(SSD/高性能云盘):存放被频繁访问的近期数据、维度表、核心聚合结果,提供亚秒级查询响应。
- 温存储层(标准云盘/对象存储标准层):存放访问频率中等的周期性分析数据。
- 冷/归档存储层(对象存储低频/归档层、磁带):存放极少访问的历史数据、合规备份,成本最低。
通过自动化策略,数据可根据创建时间、最后访问时间或业务规则在层级间自动迁移,实现性能与成本的最佳平衡。
四、 实践建议与未来展望
构建海量数据仓库存储解决方案时,建议:
- 规划先行:明确业务需求、数据规模、性能SLA和预算约束,选择匹配的架构。
- 拥抱云原生与存算分离:除非有极强的技术管控需求,优先考虑基于云对象存储的存算分离方案。
- 统一数据湖存储:将数据仓库与数据湖的底层存储统一,构建“湖仓一体”平台,避免数据孤岛和冗余。
- 重视数据治理:在存储层建立完善的数据目录、元数据管理和数据血缘追踪,确保数据可发现、可理解、可信任。
存储技术将继续向着更智能、更透明的方向发展。基于AI的自动数据分层与优化、跨云跨地域的全局数据编排、以及计算向存储的进一步下沉(如计算下推)等技术,将使海量数据仓库的存储层更加高效、经济与易用,持续释放数据价值。
如若转载,请注明出处:http://www.wzswzz.com/product/14.html
更新时间:2026-06-19 18:32:18